How to Build Maintainable Test Factories in Elixir and Phoenix
My takeaways from Jeffrey Matthias' recent talk.
Jeffrey Matthias, the coauthor with Andrea Leopardi of Testing Elixir: Effective and Robust Testing for Elixir and its Ecosystem, hosted a recent talk on building maintainable test factories that I had the pleasure to attend.
In this article, I hope to share my major takeaways from the talk. However, I’m still exploring these ideas, and have not put them to practice to learn for myself what works yet.

What is a Factory?
Factory refers to code that inserts data into your database, though a factory can also have additional behavior beyond that.
There’s a popular library in Elixir, ExMachina, which provides some out-of-the-box tools for quickly getting started with factories. Alternatively, you can also build all of the functionality yourself and build your own factories.
Factories have factory methods that allow you to build or insert data structures into your database. Here’s an example factory build with ExMachina taken from their documentation.

Tests will use a factory to arrange data for your test. You can also override values specific to the test.

How Do You Build Maintainable Factories?
Now for the interesting part. How do we build maintainable factories? I have not tried these ideas out for myself yet, but I hope to soon and can definitely see the wisdom in them.
Incidental Data vs. Intentional Data.
There are two types of data in your tests.
- Intentional data is necessary for your test to pass. Intentional data should be explicitly passed in, instead of being implicitly relied upon.
- Incidental data is not critical to the test. Your data structures expect a value, but the specific value does not matter. Incidental data can be implicit and randomized.
Explicitly Pass in Intentional Data.
You should explicitly pass intentional data into the factory method. For values that must be specific, you should not rely on implicitly created data inside of the factory method. This clarifies the relationship between the application state and behavior in your application.
Randomize Incidental Data.
Incidental data should be randomized. This helps make sure that your tests don’t have any side effects, and it forces you to specify which data is intentional in your tests.
You can use the Faker library for generating random data.

Avoid Nesting Resources.
This was probably my most immediately actionable takeaway from the talk, as I’ve been running into problems with this on my current project. When creating related resources, you should avoid building related resources in the factory itself. So the following is something you should avoid.
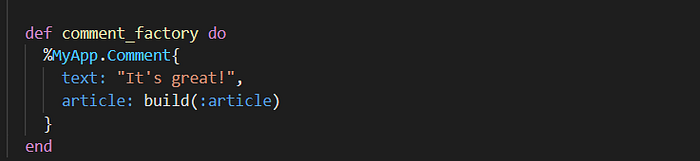
Why? Because it hides potentially intentional data. If the test relies on this data, then you should create the data explicitly in the test. Otherwise, the data is incidental and should be left empty or random.

Also, as your data structures grow and become more complex, you’ll find that you’re relying on resources nested several levels deep. This becomes a knotted mess over time. If you rely on implicitly created nested structures in your tests, then you need to modify one. You will have no examples in the rest of your codebase to follow.
However, if you have a discipline of always passing these nested values in the test when they matter, then every one of your tests acts as documentation for working with these nested resources.
Centralize Data Creation in the Factory.
In addition to handling inserting data structures into your database, Factories can also be responsible for handling the creation of common values. For example, your Factory should be responsible for generating emails, passwords, and any data you need to build data structures for your database.
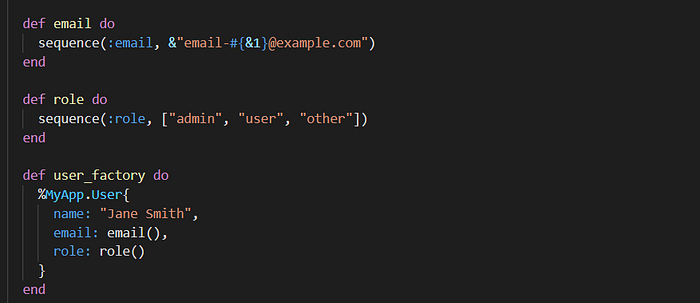
Centralizing data creation in your factory provides a convenient interface. It also means that if you decide to change how you generate data, you only have to change the code in a single place.
Separate Factories for Each Context
Instead of a single large factory, you should have different factories for each context in your application. Context refers to a phoenix context. For example, you might have an Accounts context or a Blog context depending on your application. Each of these contexts should have its own factory.
Even if Factories require similar factory methods, unless the factory method is identical for every context, you should not share factory methods between different factories.
For example, most contexts will require a user_factory method. However, contexts likely rely on different user properties, and you don’t need to build out a full user for them. So instead, you explicitly declare which fields matter for the context. It also saves time in your tests.
You may consider creating a Factory Template module that allows you to share the data generation functions between factories and create context-specific factory methods.
Separate Schema’s For Each Context
This was by far the most personally mind-blowing idea. First, you can define different schemas for each context in your application. Then, when the context interacts with that schema, it shares the same table as other contexts in your application but relies on different fields.
I understand this idea the least but am the most excited by it, and I look forward to reading more from Jeffrey on the topic because I can’t yet provide an adequate explanation for how to do this.
Options other than a factory
It’s important to take a moment to take a wider view of the broader testing landscape and see how some projects choose to test their codebase without factories.
Test Fixtures
On a previous codebase I worked with, we leveraged Test Fixtures. The idea behind a Test Fixture is that you call the actual code that your end-user would be interacting with. So, for example, if you need to create a user for a test, you don’t insert user data into your test database. Instead, you call the same signup method that the user triggers when interacting with your signup form.
Text fixtures often give you a very readable guide to the behavior of your test and hide the implementation details and state of your data.
However, an argument against using test fixtures is that it hides the important state. I had not considered this idea before the talk, so I’m still wrapping my head around it. But the potential advantage to factories is that you circumvent your normal application code and highlight the important state.
For example, pretend you want to test that you cannot fetch data for a deleted user. The Test Fixture would look something like this:
user = TestFixture.signUp()
TestFixture.deleteUser(user)
expectUnauthorized(getUserInfo(user))And the Factory would look something like this:
user = Factory.insert(:user, %{state: "deleted"})
expectUnauthorized(getUserInfo(user))Notice that the factory example clearly shows are being soft-deleted instead of being removed from the database. However, the TestFixture hid this important detail.
Inserting from a data file.
I have less experience with this method, but you can also insert data directly into your database from a file. So, for example, you could have a JSON file with all the data needed to create a user and use that to create your user.
Final Takeaways
There was a lot more to learn from Jeffrey, and frankly, I still have a litany of questions for him even after he kindly stayed late after the talk to let me and some other folks pick his brain.
I’m definitely looking forward to pickup up a copy of his recently published book Testing Elixir: Effective and Robust Testing for Elixir and its Ecosystem and can’t wait to learn more.
